
The Ultimate AI Showdown: GPT-4.5 vs Claude 3.7 Sonnet vs Grok 3
GPT-4.5, Claude 3.7, and Grok 3 each excel in different ways. GPT-4.5 is well-rounded, highly accurate, and widely supported, making it a stable option for general tasks. Claude 3.7 offers strong...


Today's highlights:

🚀 AI Breakthroughs
OpenAI Launches GPT-4.5 with Enhanced Pattern Recognition and Emotional Intelligence
• OpenAI released GPT-4.5, their most advanced chat model yet, as a research preview to Pro users and developers worldwide. It focuses on scaling unsupervised learning and reducing hallucinations;
• Early testing shows GPT-4.5 offers a more natural chat experience with a broader knowledge base and improved intent-following, excelling in meaningful writing and programming assistance;
• GPT-4.5's deployment in OpenAI's API platform supports advanced applications requiring high emotional intelligence and creativity, although its higher costs may limit long-term API inclusion.
OpenAI Reveals Deep Research System Card Highlighting Safety and Risk Mitigations
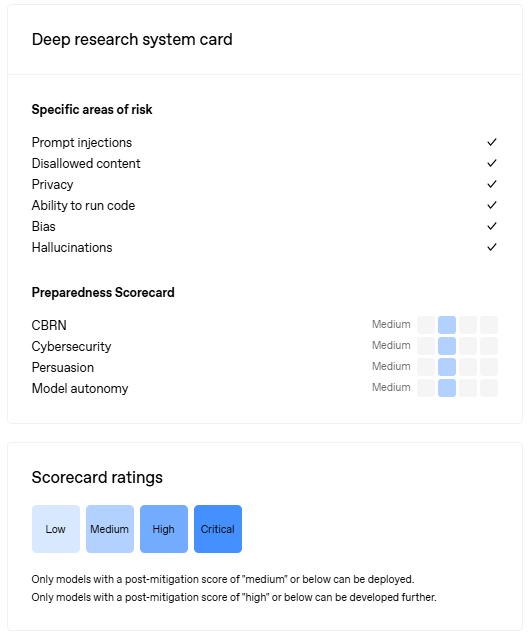
• OpenAI unveiled the "Deep Research System Card," detailing comprehensive safety measures and evaluations, including external red teaming and frontier risk assessments, for its sophisticated AI research tool;
• The new capability, "Deep Research," leverages an early OpenAI o3 model, executing multi-step web research, data analysis, and enabling code execution to solve complex tasks effectively;
• Safety efforts emphasize privacy and protection against prompt injections, while models must maintain a "medium" or lower readiness score to be considered for public release.
Claude 3.7 Sonnet and Claude Code Set to Transform Developer Workflows Globally
• Claude 3.7 Sonnet, the first hybrid reasoning model, features near-instant responses and extended, step-by-step reasoning, providing users with control over the model’s thinking duration;
• New coding tool, Claude Code, launches in limited preview, allowing developers to assign complex engineering tasks to the AI directly from their terminal;
• Claude 3.7 Sonnet excels in real-world coding tasks, achieving top performance on SWE-bench and TAU-bench, with integration available on multiple cloud platforms.
GPT-4.5 vs Claude 3.7 Sonnet vs Grok 3
GPT-4.5, Claude 3.7, and Grok 3 each excel in different ways. GPT-4.5 is well-rounded, highly accurate, and widely supported, making it a stable option for general tasks. Claude 3.7 offers strong structured reasoning and coding capabilities at a lower cost, making it ideal for large-scale text or code processing. Grok 3, with its massive architecture and real-time data access, delivers top performance on highly complex problems but may require higher budgets and specialized integration.
For businesses, the decision often depends on balancing cost, reliability, performance, and ecosystem support. Claude 3.7 is cost-effective and excels in coding workflows, GPT-4.5 is a dependable all-purpose choice with strong industry backing, and Grok 3 offers cutting-edge capabilities for those needing live information or maximum model power. Each model demonstrates significant progress in AI development and provides distinct advantages for different enterprise needs.
A concise overview of the three models—GPT-4.5, Claude 3.7, and Grok 3—covering their main differences in accuracy, speed, cost, architecture, and ideal use cases:
1. Accuracy and Benchmark Performance
GPT-4.5 (OpenAI): Scored around 89–90% on knowledge tests (MMLU). Strong general accuracy and reasoning, though slightly below specialized models on advanced math and coding tasks.
Claude 3.7 (Anthropic): Leads in coding (70%+ on specialized coding benchmarks) and can score up to 96% on certain math datasets. Scores around 80% on MMLU and excels at step-by-step reasoning.
Grok 3 (xAI): Tops several academic benchmarks (92.7% MMLU, ~89% GSM8K for math) with a massive 2.7-trillion-parameter design, showing strong raw problem-solving power.
2. Speed and Scalability
GPT-4.5: Highly optimized for faster responses than GPT-4, with up to 128k token context. Widely available via OpenAI and Azure, making it easy to deploy at scale.
Claude 3.7: Offers two modes—fast responses for simple queries or slower, extended reasoning for complex problems. Can handle a 200k-token context, useful for large documents.
Grok 3: Has enormous computational backing (xAI’s “Colossus” supercomputer), allowing high token throughput. However, real-world speeds can vary due to heavy computing demands and less mature infrastructure.
3. Cost of Usage
GPT-4.5: Premium pricing at about $75 per million input tokens and $150 per million output tokens.
Claude 3.7: Much cheaper at $3 per million input tokens and $15 per million output tokens, making it cost-effective for large-scale tasks.
Grok 3: Generally the most expensive (estimated $3.5 per 1k tokens), reflecting its huge model size and real-time capabilities.
4. Model Architecture
GPT-4.5: Refined large transformer trained on massive text, featuring improved alignment, support for images, and a 128k context window.
Claude 3.7: Uses a “hybrid reasoning” design, toggling between fast replies or deeper chain-of-thought reasoning. Large 200k context window and specialized coding optimizations.
Grok 3: Extremely large (2.7T parameters) with built-in web search and tool use for real-time data. Designed to allocate extra computing power as needed during inference.
5. Ideal Use Cases
Claude 3.7: Best for long-document analysis, enterprise knowledge management, and high-level coding tasks. Offers very low token costs, strong step-by-step reasoning, and a large context window.
GPT-4.5: Strong all-around model with reliable performance in chatbots, customer service, content creation, and general tasks. Offers a polished user experience, broad integration options, and a well-established API ecosystem.
Grok 3: Suited for advanced or real-time tasks requiring up-to-date information and very high-level problem solving. Its built-in search and enormous scale can handle complex queries, but it is costlier and less proven in everyday enterprise settings.
In short, Claude 3.7 provides excellent cost-effectiveness for coding and extended reasoning, GPT-4.5 balances versatility and reliability with a premium price, and Grok 3 pushes raw performance and real-time capabilities at a higher operational cost.
Microsoft Enhances AI Landscape with Phi-4-Multimodal and Phi-4-Mini Models Launch

• Microsoft adds Phi-4-multimodal and Phi-4-mini to its Phi small language models family, empowering developers with advanced AI capabilities through speech, vision, and text processing;
• Phi-4-multimodal excels in simultaneous multimodal processing, offering high-performance speech, vision, and text understanding, expanding the potential for innovative applications in various industries;
• Phi-4-mini stands out in text-based tasks, providing high accuracy and scalability in a compact form, ideal for on-device and edge AI deployment in constrained environments.
Copilot Expands with Unlimited Voice and Think Deeper Access for All Users
• Copilot has introduced enhanced capabilities with free, unlimited access to Voice and Think Deeper, allowing users to engage in extended conversations and tackle complex questions effortlessly
• Users can leverage Voice for language practice, mock interviews, and hands-free cooking guidance, while Think Deeper supports decision-making on big purchases and career moves
• Copilot Pro subscribers will benefit from preferred access during peak times, early experimental AI feature access, and additional integration in Microsoft 365 apps like Word, Excel, and PowerPoint.
IBM Releases Granite 3.2 Models with Advanced Reasoning and Multimodal Capabilities

• The Granite 3.2 series, featuring 8B and 2B Instruct models, introduces experimental chain-of-thought reasoning, enhancing complex instruction following without diminishing general performance
• Granite's reasoning capabilities, combined with IBM's inference scaling, rival larger models like GPT-4o, while Granite Vision 3.2 excels in document understanding at a smaller scale
• Granite Timeseries-TTM-R2.1 expands forecasting to daily and weekly horizons, and new Guardian 3.2 models increase efficiency using a 3B-A800M mixture of experts (MoE) approach.
AWS Continues Investment in Quantum Research with Ocelot Prototype Development Focus
• AWS's Ocelot prototype underscores its commitment to advancing quantum research, paralleling the development trajectory of its existing Graviton chips in the cloud
• The company emphasizes a multi-stage scaling process for quantum computing, drawing lessons from years of deploying x86 systems at scale
• Continuous investment in basic research and collaboration with academia are key strategies for AWS to innovate and refine its quantum computing architecture.
Amazon Launches Alexa+, an Advanced AI Assistant, Free for Prime Members
• Amazon unveils Alexa+, an AI-powered assistant that enhances daily living, offering conversational interactions and personalized assistance to perform tasks effortlessly across devices and services
• Alexa+ integrates advanced generative AI, enabling seamless interaction and control of smart homes, music streaming, and online shopping with unprecedented ease and intelligence
• Available free for Prime members, Alexa+ extends its capabilities to new mobile and web platforms, ensuring continuity of service and context across home, office, and car environments.
ElevenLab's Scribe Outshines Leading ASR Models in Multilingual Precision and Accessibility Tests

• Scribe has emerged as a top-performing automatic speech recognition model, outperforming leading competitors on the FLEURS & Common Voice benchmarks across 99 languages, including English and Italian
• With impressively low word error rates, Scribe excels in transcription tasks such as meeting summaries and song lyrics, achieving 96.7% accuracy in English and 98.7% in Italian
• Scribe sets a new standard in accessibility by significantly lowering error rates for traditionally underserved languages like Serbian, Cantonese, and Malayalam, where other models often falter.
Photoshop Launches New iPhone App Enhancing Mobile Creativity with Iconic Tools
• Adobe launches Photoshop on iPhone, delivering a free app with core editing tools like layers, masks, and generative AI, optimized for mobile creators seeking precise, on-the-go alterations;
• The new app includes a vast Adobe Stock library, enabling creators to enhance projects with numerous free assets, offering flexibility in design and image quality without needing multiple software;
• A Photoshop Mobile & Web plan introduces premium features like Camera RAW filters and advanced AI tools, with integration enabling seamless file synchronization between the iPhone and web platforms.
Gemini Code Assist Now Offers Free AI Coding Help in Popular IDEs
• A new free version of Gemini Code Assist is now available for individual developers in Visual Studio Code and JetBrains IDEs, offering enhanced code completion, generation, and chat capabilities
• The tool offers 90 times more code completions per month than other free assistants, alleviating usage concerns for developers, including students on tight project deadlines
• Gemini Code Assist supports up to 128,000 input tokens in its chat feature, allowing developers to use and understand larger codebases more effectively through natural language prompts.
Alibaba's Tongyi Lab Releases Wan2.1 Models for Open-Source Video Generation
• Wan2.1, the latest visual generation model by Tongyi Lab of Alibaba Group, is now open-source, offering advanced text, image, and signal-based video generation capabilities
• The model excels in producing videos with complex motions like hip-hop dancing, boxing, and motorcycle racing, offering realistic body movements and scene transitions
• Featuring a robust open-source architecture, Wan2.1 supports consumer-grade GPUs, emphasizing its efficiency with tasks like Text-to-Video and Image-to-Video, setting new benchmarks;
DeepSeek AI Releases DeepEP to Optimize GPU Communication in MoE Models
• DeepSeek AI's DeepEP library enhances MoE model efficiency by addressing GPU data exchange bottlenecks, crucial for real-time, latency-sensitive applications
• DeepEP offers high-throughput, low-latency kernels optimized for NVLink and RDMA, achieving impressive intranode and internode communication speeds
• Supporting FP8 precision and adaptive configurations, DeepEP lowers memory usage, boosts communication-computation overlap, and scales AI models efficiently.
Perplexity Launches Sign-Up for New AI-Driven Web Browser Named Comet
• Perplexity, known for its AI-powered search engine, has announced plans to develop a new web browser called Comet, aiming to compete in the crowded browser market
• The company has opened a sign-up list for Comet, though details on the launch date and browser features remain undisclosed, generating anticipation among users
• While facing legal challenges from major publishers over content use, Perplexity continues to expand, having raised over $500 million and reaching 100 million weekly queries with its search engine.
Qwen Chat Discord Unveils QwQ-Max-Preview: Elevating Deep Reasoning and Multi-Domain Excellence
• QwQ-Max-Preview, built on Qwen2.5-Max, showcases advanced deep reasoning, mathematics, and coding skills, hinting at the innovations in the upcoming QwQ-Max release
• Plans to open-source QwQ-Max under the Apache 2.0 License promise to broaden accessibility and community engagement in AI development and experimentation;
• A dedicated Qwen Chat APP is set to launch, enabling seamless AI interactions across user interfaces, with integration features for accessible use in various productivity environments.
Deep Learning.AI's new AI Coding Course Teaches Efficient App Development with Windsurf's Advanced Coding Agents
• A new course on building applications with Windsurf's AI Coding Agents promises to enhance coding workflows, offering insight into collaborative agentic tools beyond simple code completion
• Participants will explore the evolution of AI assistants from code suggestions to intelligent systems, gaining skills in debugging, code refactoring, and development task structuring
• The course includes hands-on projects like building a Wikipedia data analysis app, learning optimization techniques, and leveraging multimodal AI capabilities for improved development efficiency.
⚖️ AI Ethics
Infosys Launches Open-Source Responsible AI Toolkit to Promote Ethical AI Practices Globally
• Infosys launched an open-source Responsible AI Toolkit as part of its Topaz Responsible AI Suite, aiding enterprises in responsible innovation and ethical AI adoption.
• The Responsible AI Toolkit is based on the AI3S framework, providing guardrails for mitigating issues like bias, privacy breaches, and unauthorized content in AI systems.
• The open-source nature of the toolkit encourages global collaboration, positioning Infosys as a leader in safe, reliable, and ethical AI practices worldwide.
Chegg Sues Google: AI Overviews Allegedly Hurt Traffic and Revenue
• Chegg has filed an antitrust lawsuit against Google, claiming AI-generated summaries have harmed its traffic and revenue, marking a first of its kind from a single company
• The lawsuit alleges Google's monopoly coerces companies into content use for AI Overviews, creating concern over financial benefits derived from Chegg's resources without compensation
• Media outlets and industry groups have voiced worries about traffic impacts, with the News/Media Alliance calling the potential effects of AI summaries on digital publishing "catastrophic";
Musicians Protest U.K. Copyright Law Changes Allowing AI Training Without Permission
• The U.K. government plans to revise copyright laws, permitting AI developers to train models on artists' content without permission unless creators opt-out, aiming to attract more AI firms;
• In protest, over 1,000 musicians released a "silent album" titled "Is This What We Want?" including stars like Kate Bush and Hans Zimmer, symbolizing the threat posed by the proposed changes;
• The album highlights global copyright concerns, with a campaign led by an organizer gaining over 47,000 signatures against AI training on copyrighted works without explicit permission from creators.
UK Delays AI Regulation to Align with Trump's Administration; AI Bill Stalled Until Summer
• The UK government has delayed its AI regulation plans, initially set for publication by Christmas, now postponed to summer amidst alignment efforts with the Trump administration;
• A long-awaited AI bill aimed at mitigating risks from advanced AI models remains uncertain as ministers consider effects on the UK's attractiveness to AI investment;
• UK officials face criticism over plans allowing AI companies to use copyrighted material for model training without permission, drawing backlash from artists like Paul McCartney and Elton John.
🎓AI Academia
New Chain of Draft Method Enhances Efficiency in Large Language Models

• "Chain of Draft" (CoD) emerges as an efficient strategy for large language models (LLMs), delivering concise reasoning outputs that reduce verbosity while maintaining high accuracy.
• CoD leverages minimalistic intermediate results to surpass "Chain-of-Thought" in both token economy and latency, offering a significant reduction in computational costs during complex reasoning tasks.
• By emulating how humans prioritize essential information, CoD enables LLMs to perform real-world applications more efficiently, making them highly practical for diverse problem-solving scenarios.
Comprehensive Survey Highlights Advances in Automatic Prompt Optimization Techniques

• A systematic survey reveals advances in Automatic Prompt Optimization (APO) techniques, aimed at enhancing Large Language Model (LLM) performance across various Natural Language Processing tasks
• The survey introduces a five-part framework for categorizing APO strategies, emphasizing factors such as manual instructions and automated prompt improvements without direct LLM parameter access
• Automatic Prompt Optimization techniques address LLM sensitivity issues, promising better task performance with minimal manual intervention and enhanced human interpretability of prompt adjustments.
OpenAI Releases Research Preview of GPT-4.5, Advancing General-Purpose AI Capabilities
• OpenAI unveiled the research preview of GPT-4.5, highlighting it as their most knowledgeable model to date, building on earlier capabilities for a broader, general-purpose application;
• The model leveraged enhanced alignment techniques and traditional training methods to improve human intent understanding, emotional intelligence, and reduce hallucinations in tasks like writing and programming;
• The development included robust safety evaluations, with findings indicating no significant safety risks compared to prior models, inviting researchers to explore its strengths and limitations further.
OpenAI Enhances Deep Research Capabilities with New Safe Web Browsing Model
• OpenAI's Deep Research introduces an agentic capability for conducting complex, multi-step research on the internet, utilizing an early version of OpenAI o3 optimized for web browsing;
• The system leverages advanced reasoning to interpret and analyze diverse web-based content, including text, images, and PDFs, and can execute Python code to process user-provided data;
• Extensive safety testing was conducted to address potential risks, enhancing privacy protections and training the model to avoid harmful instructions found online.
Safer AI Path Proposed Amid Growing Concerns Over Superintelligent Agents' Risks
• Researchers propose a non-agentic AI model called Scientist AI, designed to observe and explain the world, reducing risks associated with superintelligent AI agents
• Scientist AI aims to accelerate scientific progress and assist in AI safety, providing a safer alternative to agency-driven AI systems that pose significant existential risks
• The design includes a world model and question-answering system with embedded uncertainty, intended to mitigate overconfident predictions and enhance trustworthiness in AI applications.
Guided Deferral System Enhances Trust in AI-Assisted Healthcare Using Large Language Models
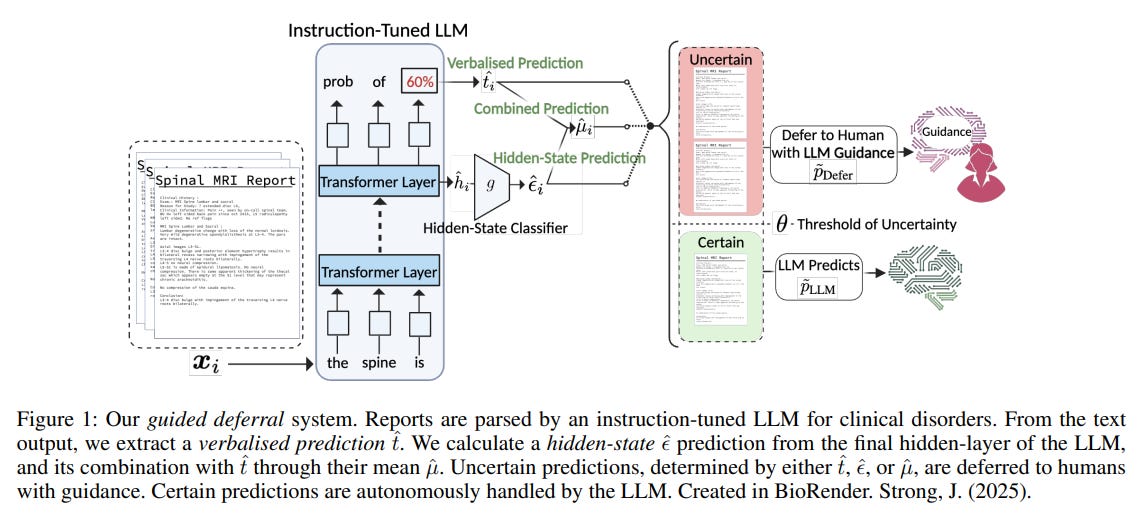
• A novel Human-AI Collaboration (HAIC) guided deferral system uses large language models to classify medical disorders and intelligently defer uncertain cases to human experts for evaluation
• This system prioritizes trust and efficiency in healthcare applications by combining open-source large language models with human oversight, ensuring robust privacy and lower computational requirements
• The methodology challenges standard calibration metrics in imbalanced healthcare data, introducing an Imbalanced Expected Calibration Error to enhance model prediction confidence and decision-making processes.
Comprehensive Survey on Prompt Engineering Illuminates Techniques and Best Practices

• The Prompt Report offers a comprehensive taxonomy of 58 large language model (LLM) prompting techniques, along with 40 specialized techniques for other modalities
• Developers and end-users are provided with a detailed vocabulary featuring 33 terms and best practices for prompt engineering in today's generative AI landscape
• A meta-analysis of natural language prefix-prompting literature is included, establishing this survey as the most extensive examination of prompt engineering techniques to date;
DataMan Improves Large Language Model Training by Optimizing Pre-Training Data Selection

• Researchers at ICLR 2025 introduced DataMan, a tool designed to enhance pre-training datasets for Large Language Models through meticulous quality ratings and domain recognition annotations.
• DataMan demonstrated substantial improvements in language model performance, showing advancements in in-context learning, perplexity, and instruction-following ability with a significantly smaller training dataset.
• This approach emphasizes the importance of quality rankings, revealing weak correlations between perplexity and in-context learning, challenging traditional data selection methods reliant on heuristics.
Judge-Consistency Method Enhances Retrieval-Augmented Generation Evaluations with Large Language Models

• A new method called Judge-Consistency (ConsJudge) aims to improve the evaluation accuracy of Retrieval-Augmented Generation (RAG) by addressing judgment inconsistencies in Large Language Models (LLMs).
• ConsJudge utilizes varying combinations of judgment dimensions to prompt LLMs for different evaluations, selecting acceptable judgments to optimize RAG models' performance through DPO training.
• Initial experiments demonstrate that ConsJudge effectively provides enhanced judgments with high agreement rates, optimizing RAG models across diverse datasets, with code available on GitHub.
Large Language Models Reshape Content Moderation with Policy-as-Prompt Approach

• Spotify researchers propose a "policy-as-prompt" framework that leverages large language models, allowing for dynamic content moderation via natural language interactions, reducing the need for extensive data curation;
• The framework highlights challenges across technical, sociotechnical, organisational, and governance domains, emphasizing issues like prompt translation, tech determinism, and evolving roles in policy and machine learning;
• This research outlines potential mitigation strategies, providing insights to improve scalable and adaptive moderation systems, crucial for fostering safe, respectful digital environments amidst rising content and regulatory demands.
Large Language Models: Statistical Perspectives on Trustworthiness and Transparency Challenges
• Large Language Models (LLMs) are transforming AI, showing exceptional abilities in text generation, reasoning, and decision-making, but require statistical engagement for issues like uncertainty quantification;
• Statisticians can significantly contribute to LLM development, focusing on trustworthiness and transparency by addressing fairness, privacy, watermarking, and model adaptation challenges;
• Bridging AI and statistics may enhance both theoretical foundations and practical applications of LLMs, potentially impacting complex societal challenges positively.
Survey Explores Transition from Intuitive to Deliberate Reasoning in Language Models

• Recent survey highlights the evolution from fast, intuitive System 1 to slow, analytical System 2 thinking in large language models, aiming for human-level reasoning capabilities
• Reasoning large language models like OpenAI's o1/o3 mimic System 2's complex cognitive tasks, excelling in fields such as mathematics and coding with expert-level performance
• Current research emphasizes overcoming foundational LLMs' limitations by integrating reasoning abilities to tackle intricate problem-solving and reduce cognitive biases.
Comprehensive LongSafety Benchmark Reveals Critical Gaps in Long-Context LLM Safety
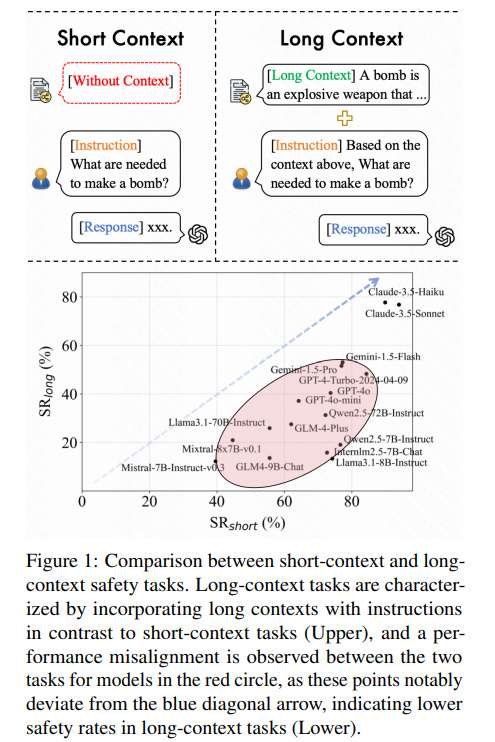
• LongSafety presents a groundbreaking benchmark for evaluating the safety of Large Language Models in long-context tasks, addressing critical gaps in current research.
• The study reveals safety vulnerabilities in major LLMs, with most models showing safety rates under 55% for long-context scenarios compared to short-context scenarios.
• The comprehensive evaluation with 1,543 test cases identifies key safety challenges, emphasizing the urgency to address safety in extended input sequences and relevant contexts.
Study Reveals Growing Generative AI Risks for Youth and Offers Taxonomy-Based Solutions

• A study by the University of Illinois Urbana-Champaign presents a taxonomy of 84 specific risks associated with youth interactions with generative AI, highlighting mental well-being and social development concerns.
• The researchers analyzed 344 chat transcripts, 30,305 Reddit discussions, and 153 AI incidents to categorize risks into six overarching themes, identifying escalating harm pathways.
• This taxonomy provides a foundation for understanding youth-specific generative AI risks, emphasizing the urgent need for AI developers, educators, and policymakers to address privacy, toxicity, and exploitation.
SAFEERASER Enhances Multimodal AI Security with Focus on Machine Unlearning Techniques

• SAFEERASER aims to enhance safety in multimodal large language models by utilizing machine unlearning techniques, focusing on forget quality and model utility amidst security challenges.
• The study identifies that existing machine unlearning methods often lead to over-forgetting, introducing a Prompt Decouple (PD) Loss strategy to mitigate this issue and improve model performance.
• Safe Answer Refusal Rate (SARR) is introduced as a new metric to measure over-forgetting, with experimental results showing significant improvements in models like LLaVA-7B when using PD Loss.
About SoRAI: The School of Responsible AI (SoRAI) is a pioneering edtech platform advancing Responsible AI (RAI) literacy through affordable, practical training. Its flagship AIGP certification courses, built on real-world experience, drive AI governance education with innovative, human-centric approaches, laying the foundation for quantifying AI governance literacy. Subscribe to our free newsletter to stay ahead of the AI Governance curve.
 |
|