
Teaching AI to Speak 'Privacy': The Need for "Trustworthy" AI-based Privacy Assistants
New research reveals a shocking truth: AI systems meant to explain privacy policies might actually be misleading us! These AIs can give answers that sound right but might be wrong to a certain degree.

In an era where our digital footprints are expanding rapidly, understanding and managing our privacy has become more crucial than ever. Enter the researchers from the University of Maryland, Baltimore County (UMBC) & the Portland State University. Their groundbreaking work on GenAIPABench is paving the way for more reliable AI-powered privacy assistants.
The team has developed a comprehensive benchmark to evaluate how well AI systems can interpret and communicate privacy policies. Their work addresses a critical need in our increasingly AI-driven world: ensuring that when we ask AI about our privacy, we can trust the answers we receive.

GenAIPABench includes:
1) A set of questions about privacy policies and data protection regulations, with annotated answers for various organizations and regulations;
2) Metrics to assess the accuracy, relevance, and consistency of responses; and
3) A tool for generating prompts to introduce privacy documents and varied privacy questions to test system robustness.
Researchers evaluated three leading genAI systems—ChatGPT-4, Bard, and Bing AI—using GenAIPABench to gauge their effectiveness as GenAIPAs. Here are the key results:
1. Performance Variability Across Systems:
The study revealed significant differences in performance among the three evaluated systems. ChatGPT-4 and BingAI consistently outperformed Bard, especially in handling complex queries and maintaining accuracy. BingAI showed superior performance in most metrics, particularly when dealing with user-generated questions and FAQs. This variability highlights the importance of choosing the right AI system for privacy-related tasks.
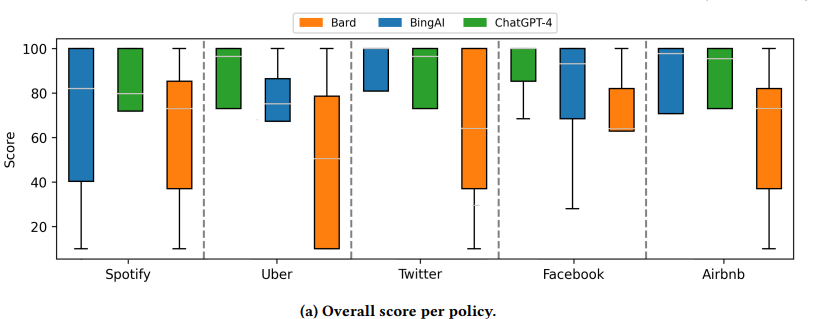
2. Challenges with Referencing and Accuracy:
All three systems, but particularly Bard and BingAI, struggled with providing accurate references to policy sections. This was evident in their consistently low scores on the Reference metric. Additionally, there were instances where the systems provided coherent and relevant responses that were factually incorrect, posing a risk of misleading users. This underscores the need for improvements in source citation and fact-checking capabilities in GenAIPAs.
3. Impact of Privacy Policy Complexity:
The systems' performance was influenced by the complexity and content of the privacy policies. Policies with higher proportions of non-existent content (like Facebook's) were generally handled better, while longer, more complex policies (like Uber's) posed greater challenges. This suggests that the effectiveness of GenAIPAs may vary depending on the specific privacy policy being analyzed, and improvements are needed to ensure consistent performance across different types of policies.
These insights highlight both the potential and the current limitations of using generative AI for privacy assistance, emphasizing areas for future development and research in this field.
In an exclusive interview with Roberto Yus, Assistant Professor Department of Computer Science and Electrical Engineering, University of Maryland, Baltimore County , we delve into the topic of AI-powered privacy assistants with the minds behind GenAIPABench to understand various aspects around this tech and related challenges:
Q1. What initially motivated you to develop GenAIPABench for evaluating Generative AI-based Privacy Assistants? How serious and widespread did you perceive the challenges around privacy policies and AI-generated responses to be when starting your research?
Privacy policies are notoriously long and complicated, and studies have shown that almost no one actually reads them. To put it in perspective, reading all the privacy policies for the websites and apps we use would take hundreds of hours! Yet, people really do want to know what companies are doing with their data. As genAI systems like ChatGPT become more popular, it's only natural that people will start asking them questions like, "Is my data on XYZ service shared with others?" instead of digging through dense policy documents.
Our concern is that while these AI-generated answers can sound clear and convincing, they often aren't accurate, and users may not be able to tell the difference. That's why we created GenAIPABench, a sort of "privacy exam" with questions based on actual privacy policies and regulations. This way, we can evaluate how well these AI systems really understand and communicate privacy information, ensuring users get the correct answers they need to protect their data.
2. Your benchmark focuses on assessing genAI systems' ability to interpret privacy policies and regulations. What were the biggest challenges you faced in creating a comprehensive evaluation framework covering-
-A set of Q&A about privacy policies and data protection regulations
-Metrics to assess the accuracy, relevance, and consistency of responses; and
-A tool for generating prompts
Our first challenge was to come up with good, representative questions for our "privacy exam." These questions needed to be comprehensive, covering everything from data sharing and retention to user rights. They also had to sound like the kind of questions people actually ask. To achieve this, we collected hundreds of real questions from FAQs, Reddit forums, and social media. We then selected the best ones and grouped similar questions together to keep the exam concise but thorough.
Another major challenge was capturing the diversity in how people ask the same question. Different individuals phrase their queries in unique ways, so we generated paraphrased versions of each question to reflect this variety while preserving their original meaning.
Evaluating the quality of the AI's answers was another complex task. We needed to ensure that the responses were not only clear and relevant but also accurate and well-referenced. This meant developing metrics to assess the clarity, relevance, and consistency of the answers, while also checking that they appropriately cited sections of the privacy policies for verification.
Lastly, crafting effective prompts for the genAI systems posed its own set of challenges. We had to ensure all systems started from a level playing field, considering they were trained on different datasets and might not have seen the privacy policy in question. We experimented with multiple prompting strategies and designed prompts that included the relevant sections of the privacy policy to ensure the AI could provide accurate and informed responses.
3. The paper mentions the potential risks of genAI systems producing inaccurate information. How do you see this challenge in the context of privacy assistants compared to other AI applications? What unique concerns arise when AI potentially misinterprets or misrepresents privacy policies?
While the challenge of producing inaccurate information isn't unique to privacy assistants, it is particularly concerning in this context. Imagine you're shopping for a smart vacuum cleaner and are worried about privacy. You might want to know if a specific model has a microphone or can capture audio. If you ask a genAI system and get an incorrect answer, such as "no, that device cannot capture audio," you could be misled into buying it, potentially compromising your privacy.
Consider also the scenario of using a health app. You might ask the AI if the app shares your health data with third parties. An incorrect response here could lead to your private health information being shared without your knowledge, potentially exposing you to unwanted marketing or even discrimination.
In the financial sector, if you're using an AI assistant to understand the privacy policies of a new banking app, an inaccurate response about how your financial data is handled could result in serious security risks, including identity theft or fraud.
Misinterpretations or misrepresentations can have significant consequences in this context, leading to breaches of trust, privacy violations, and even legal issues. Hence, ensuring that genAI systems provide precise and reliable information in the context of privacy is absolutely crucial.
4. Your results show variations in performance across different genAI systems and types of questions. What insights did you gain about the current capabilities and limitations of large language models in handling privacy-related queries?
One key finding of our research was that these systems can perform impressively well, achieving high average scores, with some systems reaching 80 out of 100, when they are asked the same questions many times. However, there's a significant downside: their performance can be highly inconsistent. In some instances, these systems scored as low as 5 out of 100, indicating that they are not robust. This means that, depending on your luck, you might receive an answer that sounds convincing but is completely incorrect.
Another critical insight was the impact of question phrasing. When we tested paraphrased versions of the same questions, the quality of the answers often deteriorated. This variability is concerning because it suggests that the clarity and accuracy of the response can depend heavily on how the question is asked. This poses a risk of misleading information, particularly for users who might phrase questions differently based on their education level or familiarity with the subject.
We also found that the length of the privacy policy, rather than the complexity of the language, was a major hurdle for these AI systems. Questions about longer policies tended to yield poorer answers, highlighting a significant limitation in processing extensive documents effectively.
Interestingly, we noticed that the systems generally performed better when answering questions about privacy regulations, like the European GDPR or California's CCPA, compared to specific company privacy policies. We believe this is because there's more extensive online discussion and training data available about these well-known regulations, which the AI systems have been exposed to more frequently.
5. Considering the computational resources required for large language models, how do you envision balancing the need for sophisticated privacy assistants with resource efficiency? Are there particular approaches you think could help make GenAIPAs more accessible and sustainable?
While our work primarily focused on evaluating the quality of AI-generated answers rather than the computational resources required, it's clear that the resource demands of large language models are a significant consideration. Training these models, especially to specialize in privacy-related expertise, can be resource-intensive.
However, the research community is actively exploring innovative methods to help with sustainability. One promising approach is fine-tuning pre-existing models rather than training new ones from scratch. This method would involve adapting an already trained model to specialize in privacy by using curated privacy documents. It's a much more resource-efficient way to achieve high-quality, specialized performance.
Another exciting technique is Retrieval-Augmented Generation (RAG). This approach involves fetching relevant information from external sources to answer user queries. For example, when asked about a specific privacy policy, the system could retrieve and include the relevant section of the policy in its response, thereby reducing the need for extensive retraining.
In our lab, we are exploring these and other approaches to find the best balance between sophistication and resource efficiency. While it's still early days, these techniques show a lot of promise. They could make advanced privacy assistants not only more powerful and reliable but also more accessible and sustainable for widespread use.
6. Given the growing focus on AI regulation, do you believe that standardized testing of AI systems for privacy-related tasks, such as with GenAIPABench, should become mandatory? How might such requirements impact both academic research and commercial AI development in the privacy domain?
Whether standardized testing of AI systems for privacy-related tasks should become mandatory is ultimately up to customers and legislators to decide. However, from our perspective, it's crucial to continue evaluating these systems and making our findings accessible to the public, enabling people to make informed decisions.
I personally believe companies developing genAI systems should routinely use benchmarks like GenAIPABench to assess their performance. This practice helps them understand the impact of their technology and take necessary precautions to ensure responsible responses. For example, if they discover that their systems struggle with certain types of privacy questions based on a standardized benchmark, they could either avoid answering those questions or encourage users to refer directly to the privacy policy for verification.
While thorough evaluation before deploying AI systems (or their updates) might require additional effort and could delay deployment, it is a responsible approach. It ensures that customers benefit from more reliable and accurate technology. The research community plays a vital role in this process, not only by designing these tests but also by addressing the issues identified through such evaluations.
7. Looking ahead, what do you see as the most promising directions for improving GenAIPAs? Are there particular techniques or approaches you're excited about that could enhance their accuracy, consistency, and overall reliability in interpreting and communicating privacy information?
We are actively working on this topic in the DAMS lab at UMBC, and there are several promising directions for improving Generative AI Privacy Assistants (GenAIPAs). One exciting approach, that I briefly described before, involves fine-tuning pre-existing models and developing advanced Retrieval-Augmented Generation (RAG) techniques. These methods can significantly enhance the accuracy of AI-generated answers by leveraging curated privacy documents and fetching relevant information from external sources.
Beyond these, there are other intriguing ideas to explore. For instance, privacy policies can be challenging to interpret even for experts, which makes the task even harder for AI systems. One potential solution is to preprocess these privacy documents to simplify them and reduce ambiguity. This could involve using data from other curated sources or expert annotations to create clearer, more straightforward versions of privacy policies before training the AI systems on them. This preprocessing step could improve the AI's performance by providing it with more easily digestible and accurate information.
We are excited to explore these, and other, avenues and contribute to the development of smarter, more trustworthy privacy assistants based on genAI.
The GenAIPABench research provides crucial insights into the capabilities and limitations of AI-powered privacy assistants. The study reveals that while current AI systems show promise in interpreting privacy policies and regulations, they face significant challenges in consistency, accuracy, and proper referencing. The researchers highlight the potential risks of AI systems providing coherent but incorrect information, which could mislead users about their privacy rights. They also note that AI performance varies depending on the complexity of privacy policies and the phrasing of questions. The team emphasizes the need for standardized testing of AI systems in privacy-related tasks and explores potential solutions such as fine-tuning pre-existing models and using Retrieval-Augmented Generation (RAG) techniques. Overall, the research underscores the importance of continued evaluation and improvement of AI systems to ensure they provide reliable and trustworthy assistance in understanding and managing privacy information.
The GenAIPABench research provides crucial insights into the capabilities and limitations of AI-powered privacy assistants. The study reveals that while current AI systems show promise in interpreting privacy policies and regulations, they face significant challenges in consistency, accuracy, and proper referencing. The researchers highlight the potential risks of AI systems providing coherent but incorrect information, which could mislead users about their privacy rights. They also note that AI performance varies depending on the complexity of privacy policies and the phrasing of questions. The team emphasizes the need for standardized testing of AI systems in privacy-related tasks and explores potential solutions such as fine-tuning pre-existing models and using Retrieval-Augmented Generation (RAG) techniques. Overall, the research underscores the importance of continued evaluation and improvement of AI systems to ensure they provide reliable and trustworthy assistance in understanding and managing privacy information.