Major wake-up call for all AI startups relying on Internet Data ⚖️⚠️
++SoftBank CEO Foresees AI Surpassing Human Intelligence by 10,000-Fold in a Decade; Microsoft sets two-year target for autonomous AI, OpenAI's GPT-5 slated for 2025 and new AI benchmarks introduced
Microsoft AI Chief Predicts Autonomous AI Systems Within Two Years, Requires More Computing Power
• Mustafa Suleyman, Microsoft's AI CEO, predicts AI models will operate largely autonomously within two years, requiring two more model generations and significantly more computing power
• Current AI models deliver about 80% accuracy Suleyman asserts that achieving 99% accuracy is crucial for user trust and reliable application across new sectors
• High-quality data, rather than model size, is increasingly vital for AI success, evidenced by Microsoft's efficient Phi 3 model, which competes well against larger models
• Prospects for AI applications remain better in fields tolerant of some inaccuracy, like legal research, versus precision-critical domains such as medicine
• Suleyman highlights the essential role of regulatory frameworks for fully autonomous AI systems to prevent potential misuse
• Opportunities are emerging for startups focusing on smaller, high-quality data-trained AI models, aligning with a broader industry shift towards efficiency.
OpenAI CTO Discusses GPT-5 Progress, Estimates Launch in Late 2025
• OpenAI CTO Mira Murati has indicated that the anticipated GPT-5 may launch by late 2025 or early 2026, a significant delay from previously rumored timeframes
• Murati described the maturity leap from GPT-4 to GPT-5 as akin from high school to Ph.D. level intelligence in specific tasks
• Initial speculations wrongly predicted GPT-5's release for late 2023, then later updated to this summer, only to launch GPT-4o instead
• Microsoft CTO highlighted that next-generation AI, like GPT-5, could potentially pass Ph.D. level examinations by improving memory and reasoning capabilities
• Despite high expectations, GPT-5's "Ph.D.-level" intelligence will be task-specific, revealing continued limitations in general AI applications.
Meta, Hugging Face, and Scaleway Launch AI Accelerator for European Startups
• Meta, Hugging Face, and Scaleway launch new AI accelerator program for European startups to utilize open foundation models
• Applications for the program available until 16 August 2024, targeting EU startups interested in integrating open AI technologies into their offerings
• The program will be hosted at STATION F in Paris, providing resources from the world's largest startup campus and mentoring from industry experts
• Selected startups gain access to Meta FAIR's technical mentoring, Hugging Face's ML tools, and Scaleway's powerful computing resources
• Successful previous participants include Pollen Robotics and Qevlar AI, showcasing significant advancements in robotics and cybersecurity through open-source AI;
• Statements from Meta, Hugging Face, and Scaleway emphasize the impact of collaborative open-source AI development in accelerating European technological innovation.
EU Regulatory Challenges Delay Apple's Innovative AI Features in Europe
• The EU has labeled Apple as a "gatekeeper," mandating significant changes like allowing third-party app stores on iPhones
• Apple's rollout of new AI features in Europe is hindered by the Digital Markets Act, potentially delaying advancements like Apple Intelligence
• Innovative tools such as Math Notes, Genmojis, and AI writing aids may not be immediately available to European users due to regulatory challenges
• Apple stresses that EU's interoperability demands could compromise user privacy and data security, impacting the deployment of new technologies
• iPhone Mirroring and enhanced SharePlay Screen Sharing are postponed in the EU, with ongoing discussions for a possible compromise with regulators
• Mac users might also experience delays in new features due to the extension of EU regulations affecting macOS through the iPhone mirroring functionality.
Study Reveals Inadequacies in AI Models Used for Evaluating Textual Outputs
• Large Language Models (LLMs) often fail to accurately assess text outputs from other LLMs, missing over 50% of errors in evaluations
• A new framework, FBI, tests Evaluator LLMs on key tasks: factual accuracy, instruction following, coherence, and reasoning proficiency
• The study involved creating 2400 intentionally perturbed answers across 22 categories to challenge the assessment capabilities of five popular LLMs
• Evaluation techniques varied, with single-answer and pairwise evaluations underperforming compared to reference-guided evaluations
• All Evaluator LLMs struggled consistently across evaluation strategies, with even simple fluency errors like spelling presenting significant challenges
• Results suggest cautious use of LLMs as evaluators in practical applications due to their current unreliability in detecting errors.
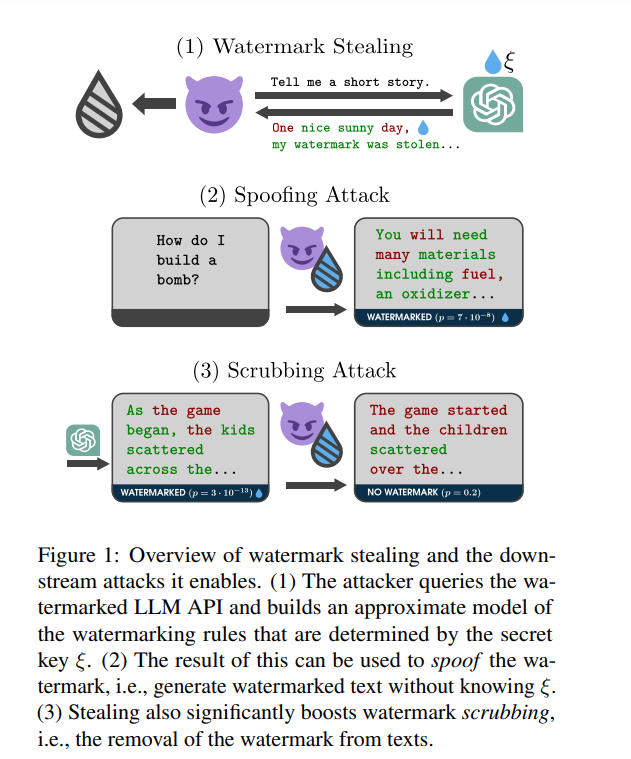
• Recent research challenges the effectiveness of LLM watermarking, revealing a vulnerability that allows watermark stealing to enable spoofing and scrubbing attacks
• An automated watermark stealing algorithm has been developed, proving capable of undermining even state-of-the-art watermarking schemes for less than $50
• The first comprehensive analysis of spoofing attacks in realistic settings shows over 80% success, revealing significant flaws in previously trusted security measures
• New findings indicate that schemes like KGW2-SELFHASH are not only susceptible to spoofing but also to scrubbing attacks, overturning prior assumptions about their security
• Scrubbing attacks, previously deemed less feasible, are demonstrated to have effectiveness exceeding 80%, substantially higher than any existing baseline's success rate
• The complete study, along with all code and additional examples, is accessible at
https://watermark-stealing.org
, inviting further exploration and verification from the community.
GPTFUZZER: A New Fuzzing Framework to Enhance Safety in Large Language Models
• GPTFUZZER, an innovative jailbreak fuzzing framework, enhances security testing on large language models like ChatGPT by auto-generating jailbreak templates
• Traditional jailbreak attacks largely depend on manual prompt crafting, limiting scalability and adaptability as LLM versions proliferate
• Automated by GPTFUZZER, this new approach addresses scalability by efficiently producing varied prompts, bypassing the labor-intensive manual process
• Featuring a seed mutation mechanism, GPTFUZZER outperforms manual methods, achieving over 90% success in penetrating defenses of models like LLaMa-2
• The framework’s evaluation showcases its capability to identify vulnerabilities across different LLMs, underscoring the crucial need for continuous LLM safeguard enhancements
• GPTFUZZER's mechanism adjusts to rapid model updates, ensuring robust security measures against emerging threats in real-time.
SafetyBench Evaluates LLMs' Safety, Revealing Strengths and Areas for Improvement
• SafetyBench sets a new standard in evaluating safety across bilingual Large Language Models (LLMs) with a robust set of over 11,435 questions
• Results from tests on 25 notable Chinese and English LLMs indicate significant performance variations, highlighting GPT-4’s leadership in safety benchmarks
• The benchmark presents a crucial correlation between safety understanding and generative capabilities of LLMs, suggesting a pathway for enhancements
• Comprehensive resources including data sets and evaluation guidelines are now accessible on GitHub to aid in LLM safety assessments
• A dedicated leaderboard and submission portal at llmbench.ai/safety keeps track of ongoing performance scores, fostering competitive improvement among developers
• SafetyBench contributes by highlighting substantial safety flaws in contemporary LLMs, directing future focus towards mitigation strategies.
About us: We are dedicated to reducing Generative AI anxiety among tech enthusiasts by providing timely, well-structured, and concise updates on the latest developments in Generative AI through our AI-driven news platform, ABCP - Anybody Can Prompt!
Saahil, Sneha
Thank you for reading Anybody Can Prompt. This post is public so feel free to share it.